How to scrape seatgeek.com protected by DataDome in 2024?
What is Seatgeek and why to scrape it?
Seatgeek is a popular online ticket marketplace that specializes in sports, concert, and theater tickets. Founded in 2009, it has grown to become one of the largest secondary ticket platforms in the United States. Seatgeek aggregates tickets from various sources, including primary ticket sellers and resellers, offering users a comprehensive view of available tickets for events.
The platform is often targeted for web scraping due to several reasons:
- Real-time pricing information: Ticket prices on Seatgeek fluctuate based on demand, event popularity, and proximity to the event date. Scrapers aim to capture this dynamic pricing data for analysis or competitive purposes.
- Inventory tracking: Event organizers, performers, and competing ticket platforms may want to monitor ticket availability and sales trends across various events.
- Market research: Analysts and researchers might scrape Seatgeek to gather data on event popularity, pricing strategies, and consumer behavior in the ticketing industry.
- Price comparison services: Third-party services often aggregate ticket prices from multiple sources, including Seatgeek, to provide consumers with the best deals.
- Automated purchasing: Some scrapers might be designed to quickly purchase tickets for high-demand events, although this practice is generally frowned upon and actively combated by ticket platforms.
Given the value of the data available on Seatgeek, the platform has implemented strong anti-bot measures, such as DataDome, to protect its content and ensure fair access for genuine users. This creates a cat-and-mouse game between scrapers and the platform's security measures, leading to the need for increasingly sophisticated scraping techniques.
Now, let's dive into how one might approach scraping Seatgeek in 2024, keeping in mind the ethical and legal considerations of such activities.
The challenge: DataDome protection
Seatgeek is protected by DataDome. When you try to access Seatgeek using some poor datacenter IP, you will get a blocked page even without any chance to solve a CAPTCHA.
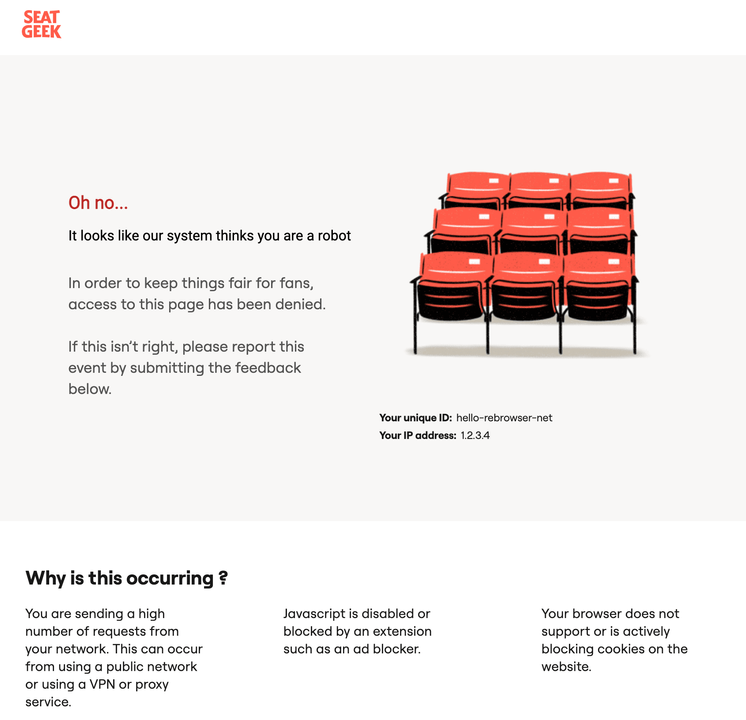
But if your IP is not that bad, you will see a puzzle page.
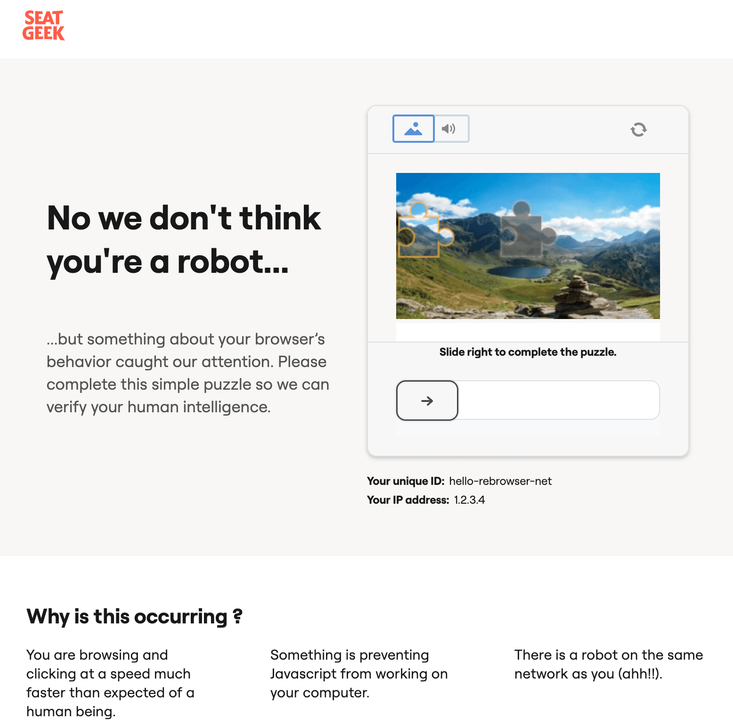
DataDome is famous for their article about how they detect automation libraries. And they actually do detect them using this exact method they mentioned in their article. So, if we use vanilla puppeteer or playwright out of the box, we will immediately get a CAPTCHA page which actually is not even easy to pass manually because they flag you really badly if they see Runtime.Enable leak from you.
But gladly we've released a set of patches (rebrowser-patches) that fix this leak. So, instead of puppeteer-core we just use rebrowser-puppeteer-core, and boom... this CAPTCHA window is gone. Moreover, it was even enough to use plain datacenter proxies with average reputation; we didn't need to leverage our pool of high-quality mobile and residential proxies for this project.
# before (page with CAPTCHA) import puppeteer from 'puppeteer-core' # after (no CAPTCHA) import puppeteer from 'rebrowser-puppeteer-core'
Now we're on the page, and it seems that the list of available tickets loads asynchronously, as we can see some loading animation on the left when the page is loaded.
Going to the network tab of devtools and doing some investigation, we can see our target request: https://seatgeek.com/api/event_listings_v2.
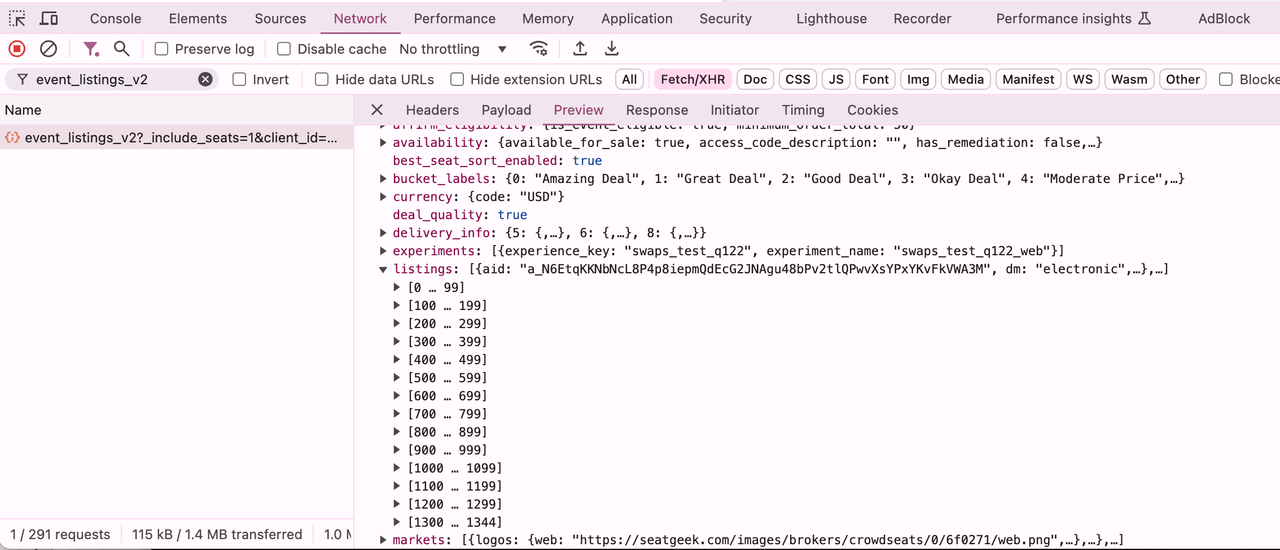
As you can see, there is a listings array that contains 1344 items; these are the actual tickets we see in the UI. If we expand each item, we will see a bunch of keys and values. They're shortened for some reason, but it's quite easy to map UI fields with the keys of the object.
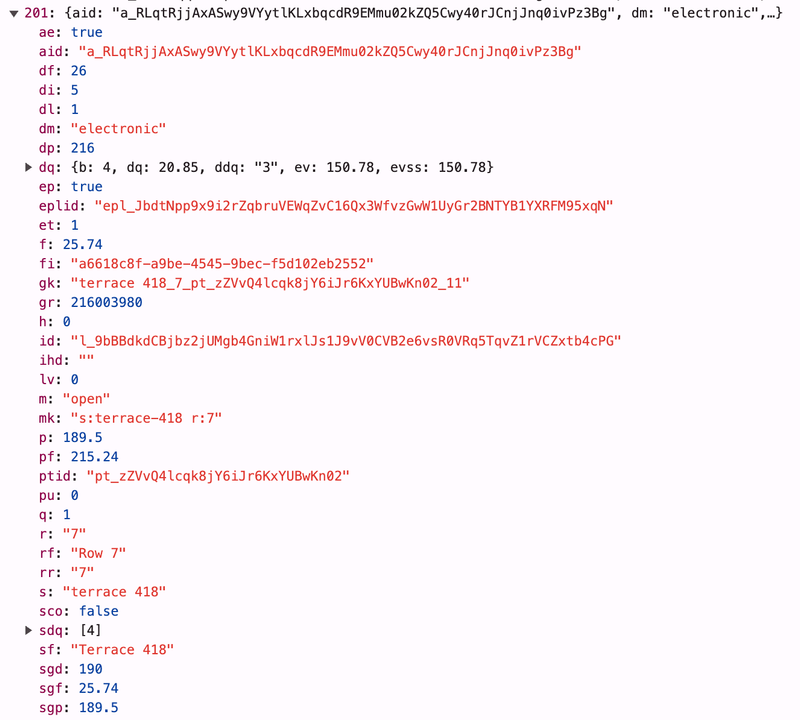
Use LLM for fields mapping
Pro-tip: you can feed this object to ChatGPT and also upload a screenshot of the listing item, and ask to make a JSON schema for mapping. For example, we used the next prompt:
Here is a screenshot of UI and a piece of JSON representing this item. Make a JSON that maps fields from the original JSON and fields on UI.
And here is what GPT-4 responded:
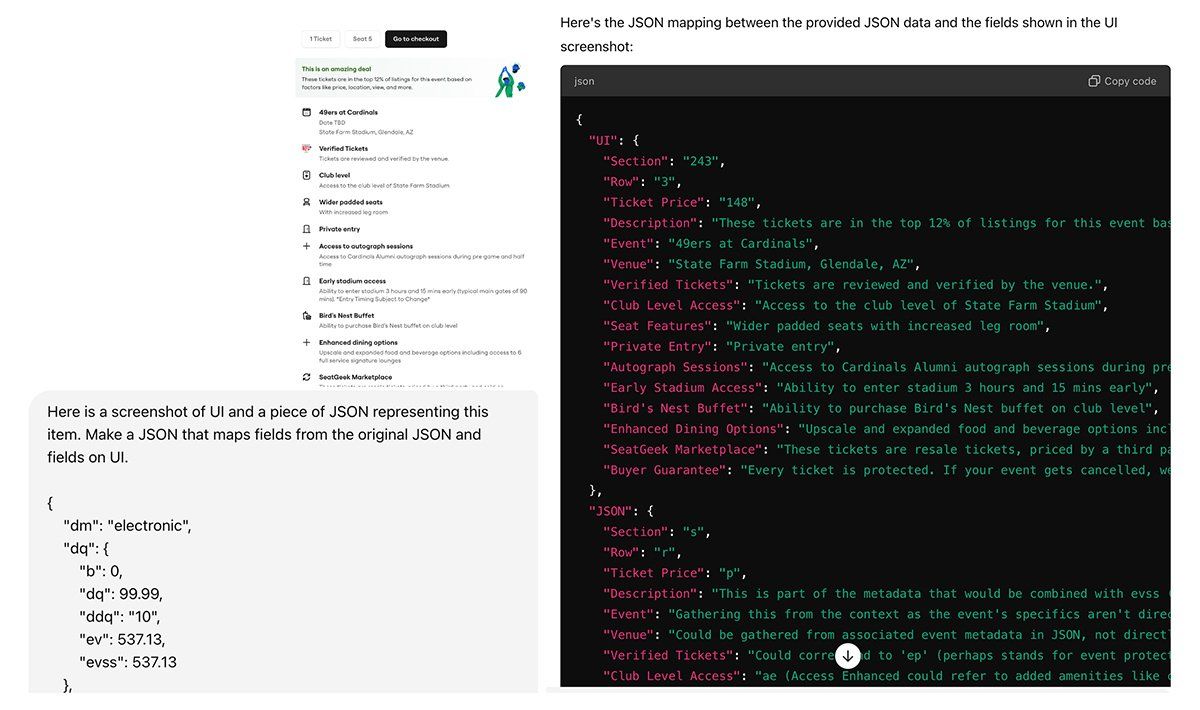
As you can see, it's quite useful, and with some further adjustments could make the mapping task much easier.
JS code to intercept event listings request
Now we can write some JS code using Puppeteer that will intercept this specific request.
page.on('requestfinished', async (request) => {
if (request.url().includes('event_listings_v2')) {
const response = await request.response()
const responseBody = await response.buffer()
console.log('[event_listings_v2] response:', responseBody)
}
})
await page.goto('https://seatgeek.com/a-day-to-remember-tickets/las-vegas-nevada-fontainebleau-2-2024-10-17-6-30-pm/concert/17051909')
For Playwright and other libraries the approach will be pretty much the same.
How to scale web scraping operation
The next big thing will be the scaling question. How to scrape multiple events automatically and store all this data properly? One possible approach could be to save a cookie that you've got after visiting the page with a browser, and then use it for raw requests using curl_cffi or any other request library. Probably you will have to renew the cookie from time to time as it's going to expire after X minutes or X requests (depends on their configuration).
Also, you can leverage our cloud products and save a lot of resources on infrastructure management and detection cat-and-mouse game. Also, we do consult companies about the best ways to build related products, please see our unique early customers offer.
Heads up: usually anti-bot companies actively monitor the community and watch for posts like this and react quite fast, improving their systems. There is a chance that this specific approach won't work after this post is published, but it could still be useful for general understanding of web scraping. Don't give up, you can always contact us for any help and consulting.
Disclaimer: This article is provided for educational and informational purposes only. The author and website hosting this content do not endorse or encourage any activities that violate terms of service, laws, or ethical guidelines. Readers must respect website terms of service and adhere to all local, national, and international regulations and rules. The information presented may become outdated due to rapid changes in technology and security measures. Readers use this information at their own risk and are solely responsible for ensuring their actions comply with all applicable laws, regulations, and terms of service. The author and website disclaim all liability for any consequences resulting from the use or misuse of this information. By reading this article, you agree to use the knowledge gained responsibly and ethically.





